
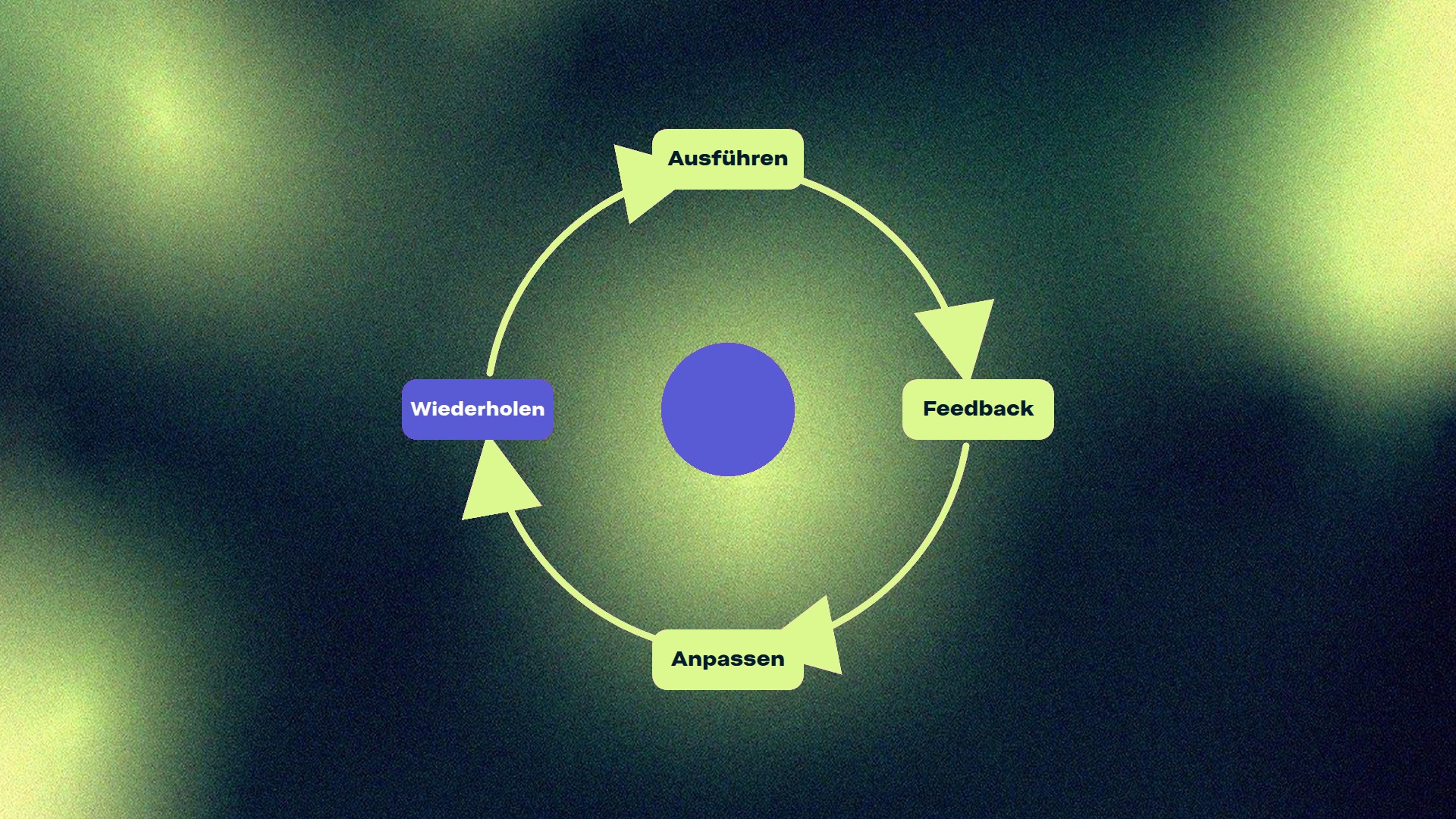
Der Lernloop: Wie dein KI-Betriebssystem mit der Zeit besser wird
Die Schicht über allem. Warum Feedback im Chat verpufft und im System bleibt, und wo welche Korrektur hingehört.
Hoi und herzlich willkomma zu den Büro für KI-Insights 👋🏽
Wir bauen bei uns im Büro für KI inzwischen seit Monaten an unserem eigenen KI-Betriebssystem.
Und dabei fällt mir immer wieder dieselbe Beobachtung auf: Es spielt weniger eine Rolle, wie gut das erste Ergebnis ist. Was wirklich zählt, ist was mit Fehlern passiert.
Landen Korrekturen irgendwo, wo sie beim nächsten Mal noch da sind? Oder verschwinden sie im nächsten Chat-Verlauf?
Das ist das Thema dieser letzten Ausgabe der KI-Betriebssystem-Serie.
In diesem Newsletter erfährst du:
- Was der Lernloop ist und warum er kein sechster Baustein ist
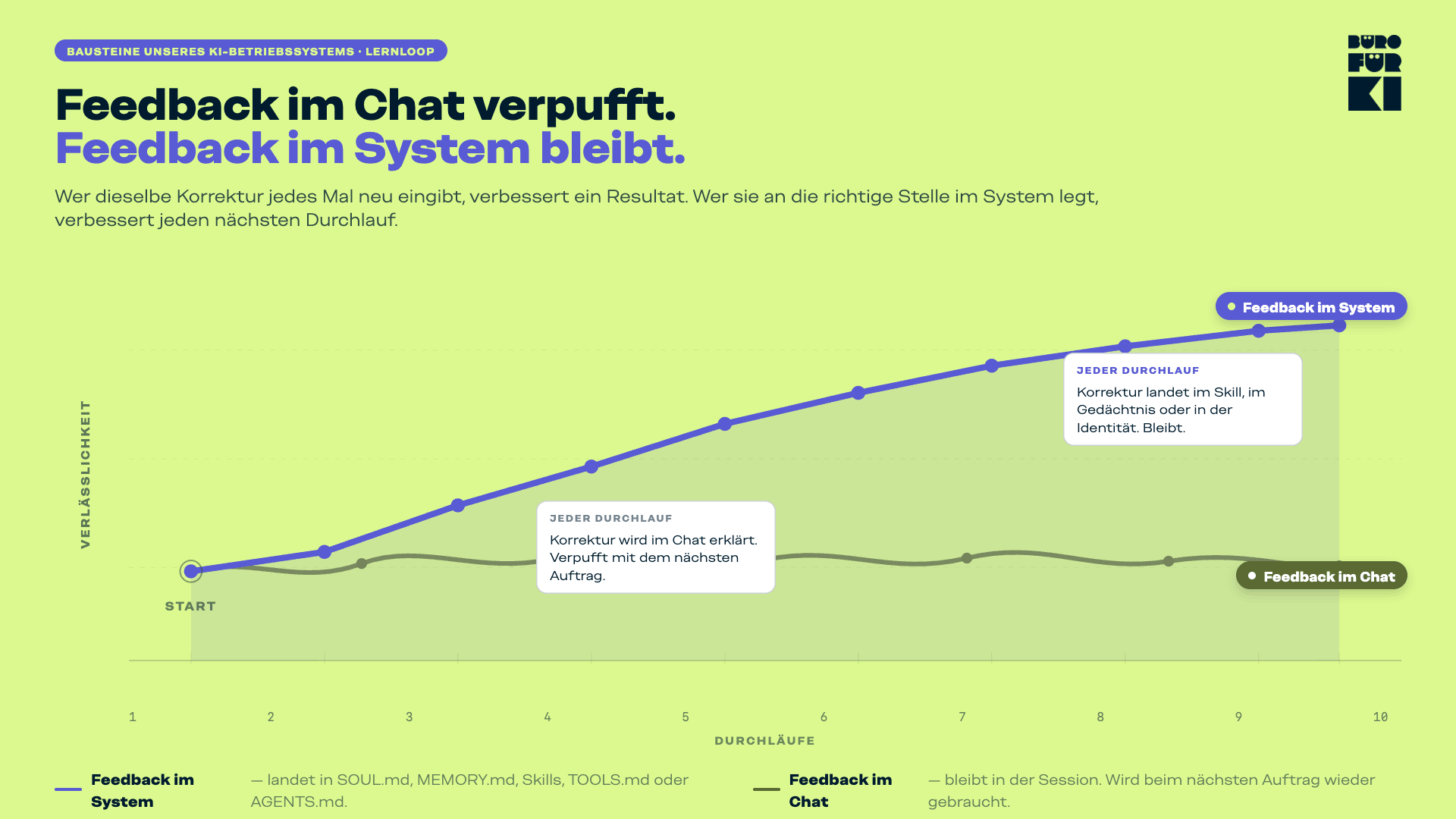
- Warum Feedback im Chat verpufft
- Wie es bei uns konkret funktioniert, mit drei Beispielen aus dem Alltag
- Welche fünf Zielorte es für Feedback gibt (das Goodie dieser Ausgabe)
- Was das für dich bedeutet, auch wenn du noch kein KI-Betriebssystem hast
Let's dive in 🤓🤿
Was nach den fünf Bausteinen kommt
Die letzten fünf Ausgaben haben ein KI-Betriebssystem von Grund auf aufgebaut.
Identität hat die Frage beantwortet, wer der Agent ist. Gedächtnis, was er weiss. Skills, wie er Aufgaben ausführt. Schnittstellen, womit er verbunden ist. Governance, was er darf und was nicht.
Den Überblick findest du hier: Die fünf Bausteine unseres KI-Betriebssystems.
Es ist unser System. Gebaut für uns im Büro für KI, über Monate hinweg, im echten Betrieb. SOUL.md, MEMORY.md, Skills, Governance, der Lernloop, das ist unsere eigene Infrastruktur, mit der wir täglich arbeiten.
Wir teilen das, weil wir glauben, dass dieser Ansatz für viele Organisationen relevant ist.
Fünf Bausteine, fünf Ausgaben. Und trotzdem fehlt noch etwas.
Keiner der fünf Bausteine beantwortet eine Frage, die sich erst im echten Betrieb stellt. Was passiert, wenn etwas nicht stimmt? Wie wird das System aus Fehlern besser? Und wer ist eigentlich dafür zuständig, dass Korrekturen nicht im nächsten Chat-Verlauf verschwinden?
Genau das ist der Lernloop. Kein sechster Baustein, sondern die Schicht über allem, die entscheidet, ob die anderen fünf über Zeit wirklich besser werden oder auf dem Stand vom ersten Tag stecken bleiben.

Warum Feedback im Chat verpufft
Ich beobachte das regelmässig, auch bei uns selbst.
Ein Output ist nicht ganz richtig. Man schreibt zurück: «Das war zu formal» oder «Dieser Schritt fehlt». Das Modell korrigiert. Der nächste Output in dieser Session ist besser.
Und dann, beim nächsten Auftrag, am nächsten Tag, beim nächsten Mal, passiert dasselbe wieder.
Das ist kein Zufall und auch kein Modellproblem. Das ist ein Systemdesign-Problem.
Und hier ist ein Punkt, der oft missverstanden wird: Das Modell selbst lernt nicht von dir. Nie. Egal wie oft du es korrigierst, egal wie detailliert du Feedback gibst, die Gewichte des Modells, also das, was Claude oder GPT eigentlich ist, bleiben unverändert. Die werden nur durch Training bei Anthropic oder OpenAI angepasst, nicht durch deine Konversationen.
Was sich aber verändern kann, ist das System um das Modell herum. Konfiguration, Gedächtnis, Skills, Anweisungen. Das ist die Schicht, die wir kontrollieren können. Und genau dort passiert das Lernen bei unserem System.
Dass das kein Randthema ist, zeigt ein Beispiel vom Anfang Mai: Anthropic hat auf ihrer Entwicklerkonferenz «Code with Claude» eine neue Funktion namens «Dreaming» vorgestellt. Ein Prozess, der vergangene Sessions automatisch reviewt, Muster und Fehler extrahiert und das Gedächtnis des Agenten strukturiert verbessert. Der Effekt: Systeme die besser werden, ohne dass das Modell selbst angepasst wird. MindStudio hat es treffend formuliert: «Model improvement requires Anthropic; agent improvement can happen continuously through good memory design.»
Wir machen dasselbe. Und genau darum geht es in diesem Newsletter.
Der Unterschied zwischen einem KI-Tool und einem KI-System oder Betriebssystem liegt für mich genau hier. Ein Tool macht, was du sagst.
Ein System wird mit der Zeit besser, weil Korrekturen irgendwo ankommen und bleiben.
Wie es bei uns konkret läuft
Drei Beispiele aus unserem Alltag.
Kreditkartenabrechnungen in Bexio
Im Mai haben wir bei uns im Büro für KI angefangen, Kreditkartenabrechnungen automatisch in Bexio zu verbuchen. Früher machten wir das mit Kontera. Heute machts unser Agent. Dennoch, die erste Runde war noch nicht perfekt: Falsche Kontonummern, unscharfe Buchungstexte, Dateinamen mit automatischen Suffixen und so einiges mehr.
Alles Kleinigkeiten, die jeweils korrigierbar wären.
Aber nicht jedes Mal neu, sondern die Korrekturen (mein Feedback) sind einmal direkt in den Skill geflossen.
Seither läuft jede Abrechnung (in >90% der Fälle) sauber. Nicht weil das Modell besser geworden ist, sondern weil die Arbeitslogik sauber abgelegt ist.
Kontakte in Bexio
Wer Bexio kennt, weiss, Kontakte kann man als Privat oder Firma anlegen.
Bei der Verarbeitung von Workshop-Anmeldungen hat das System anfangs systematisch Firmenkontakte als Privatkontakte angelegt. Und umgekehrt.
Klingt nach einem Detail. Ist es aber nicht, weil genau dieses Feld in Bexio steuert, welche Felder erscheinen und wie der Kontakt korrekt strukturiert wird. Falsch angelegte Kontakte bedeuten Aufräumarbeit hinterher.
Nach dem Feedback ist die Unterscheidung im Skill festgehalten. Firma als Firma, Privat als Privat, mit den richtigen Feldern für jeden Typ. Seither ist das kein Thema mehr.
Offerten nachfassen
Vor einiger Zeit hat unser System für eine bereits bestätigte Offerte einen Nachfass-Entwurf vorbereitet, als wäre die Offerte noch offen.
Das Problem war der Ausgangspunkt: Der Mailverlauf, nicht der aktuelle Status in Bexio. Die Korrektur war einfach: Vor jedem Nachfass-Draft zuerst den Status prüfen, nicht den Mailverlauf als einzige Quelle nehmen.
Diese Regel ist jetzt im Skill. Seither wird zuerst geprüft, dann geschrieben.
Alle drei Beispiele haben dasselbe Muster: Einen Fehler, eine Korrektur, und dann eine Entscheidung. Verbessere ich nur dieses eine Resultat? Oder verbessere ich das, was das Resultat erzeugt?
Wer nur das Resultat korrigiert, macht es einmal besser. Wer das System korrigiert, macht jeden nächsten Durchlauf besser.
Wo Feedback hingehört
Nicht jedes Feedback gehört an denselben Ort. Und die meisten verlieren genau dort Zeit: sie wissen nicht, wohin mit einer Korrektur, also bleibt sie im Chat und verschwindet.
Die fünf Bausteine aus dieser Serie sind auch fünf Zielorte für Feedback.
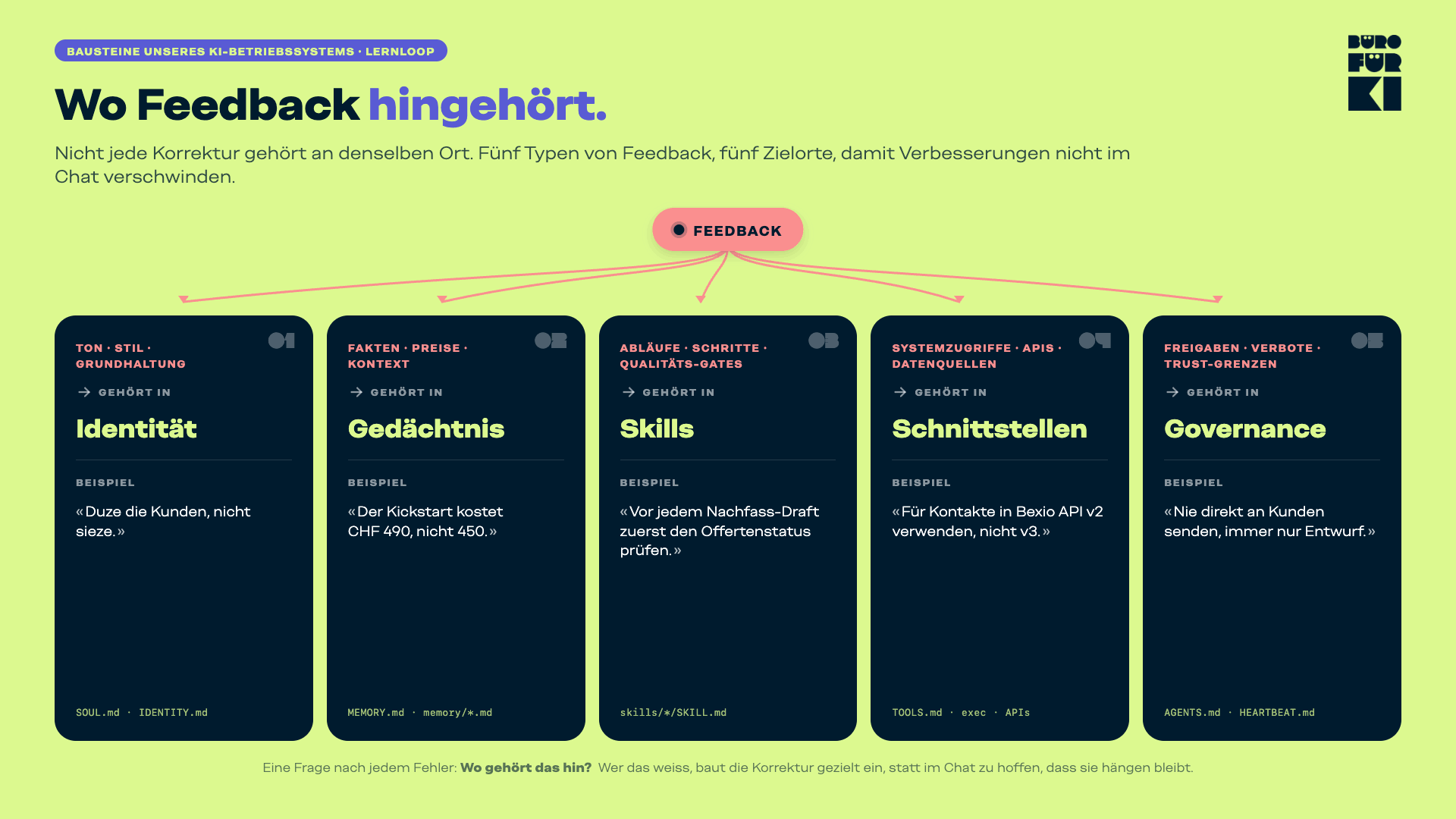
Ton, Stil, Grundhaltung → Identität
Wenn das System falsch klingt, zu steif schreibt oder in der falschen Haltung antwortet, gehört die Korrektur in die Identität. Also in die Konfiguration, die definiert, wer der Agent ist und wie er kommuniziert.
Beispiel: «Duze die Kunden, nicht sieze.» Einmal festgehalten, gilt es überall.
Fakten, Preise, Kontext → Gedächtnis
Wenn das System mit falschen Informationen arbeitet, veralteten Preisen, unbekannten Kunden, falschem Kontext, gehört die Korrektur ins Gedächtnis. Damit die richtige Information beim nächsten Mal verfügbar ist.
Beispiel: «Der KIckstart kostet CHF 490, nicht 450.» Einmal im Gedächtnis, läuft es durch alle Offerten und Mails hindurch.
Abläufe, Schritte, Qualitäts-Gates → Skills
Wenn ein Prozessschritt fehlt, in der falschen Reihenfolge läuft oder ein Qualitätsproblem immer wieder auftaucht, gehört die Korrektur in den Skill. Das sind die aufgeschriebenen Arbeitsweisen für konkrete, wiederkehrende Aufgaben.
Beispiel: «Vor jedem Nachfass-Draft zuerst den Offertenstatus prüfen.» Einmal im Skill, läuft es immer (mit immer meine ich in der Regel > 90%; 100% gibt es bei generativer KI nicht) so.
Systemzugriffe, API-Verbindungen, Datenquellen → Schnittstellen
Wenn ein Zugriff nicht klappt, Daten aus der falschen Quelle kommen oder eine Verbindung fehlerhaft ist, gehört die Korrektur in die Schnittstellen-Konfiguration.
Beispiel: «Für Kontakt-Erstellung in Bexio API v2 verwenden, nicht v3.» Das ist kein Inhaltsproblem, sondern ein Verbindungsproblem. Es gehört nicht in den Skill, sondern in die technische Konfiguration.
Freigaben, Verbote, Trust-Grenzen → Governance
Wenn das System eine Aktion ausgeführt hat, die so nicht hätte passieren sollen, gehört die Korrektur in die Governance. Also in die Regeln, die festlegen, was autonom erlaubt ist und was Freigabe braucht.
Beispiel: «Nie direkt an Kunden senden, immer nur Entwurf.»
Die Landkarte hilft bei einer konkreten Frage nach jedem Fehler: Wo gehört das hin?
Wer das weiss, kann die Korrektur gezielt einbauen, statt im Chat zu hoffen, dass sie irgendwie hängen bleibt.
Übrigens: Der Agent weiss meist anhand von meinem Feedback, wo er nachjustieren muss. Sehr sehr oft geht es in den Skill. Aber es gibt auch immer wieder Punkte, die bei anderen Bausteinen ansetzen und diese optimieren.
Was das für dein Unternehmen bedeutet
Du brauchst kein KI-Betriebssystem mit eigenen Konfigurationsdateien, um vom Lernloop zu profitieren.
Das Prinzip funktioniert auf jedem Level.
Wer mit ChatGPT, Copilot, Claude oder Langdock arbeitet, kann systematisch besser werden, wenn er oder sie z. B. die Erinnerungs-Features («Merke dir, dass...») nutzt. Oder du fügst einfach einen kurzen Text in den Custom Instructions hinzu.
Erinnerungsfunktion in ChatGPT
Custom Instructions (Individuelle Hinweise) in ChatGPT
Das grösste Risiko bei KI im Betrieb ist nicht, dass Fehler passieren. Fehler passieren immer, in jedem System, mit jedem Tool. Das grösste Risiko ist, dass dieselben Fehler immer wieder passieren, weil niemand weiss, wohin das Feedback eigentlich gehört.
Also nutze die Funktionen, die dir dein Tool gibt, um Dinge zentral abzuspeichern fürs nächste Mal. So dass du es eben nicht jedes Mal wiederholen musst.
Wo wir das gerade weiterentwickeln
Die letzten sechs Ausgaben haben beschrieben, wie wir dieses System denken. Bei uns läuft das bisher alles auf OpenClaw. Allerdings fehlt mir dort oftmals einfach die Übersicht und Möglichkeiten zur Kontrolle. Alles läuft über ein Chat-Interface (bei uns Telegram). OpenClaw selbst arbeitet direkt lokal mit dem Filesystem eines alten Laptops (Linux Ubuntu). Es ist so, wie es aktuell ist, nicht für grössere Unternehmen gedacht.
Andere bauen sich diese Kontrollierbarkeit über Tools wie Notion und nutzen z. T. auch Claude Code. Ein fix fertiges Tool, das das alles abbildet, habe ich bisher noch nicht gefunden.
Deshalb habe ich vor knapp einer Woche angefangen, die Prinzipien hinter unserem KI-Betriebssystem in eine eigene Plattform zu übersetzen. Intern nennen wir es den AgentHub.
Der Gedanke ist folgender: Alles, was wir in dieser Serie durchgegangen sind, Identität, Gedächtnis, Skills, Schnittstellen, Governance, Lernloop, in eine einzige Plattform giessen. Angepasst auf den Alltag in kleineren und mittleren Unternehmen.
Die ehrliche Hürde
Bevor du jetzt loslegst, eine ehrliche Beobachtung: Der Lernloop scheitert selten an der Technik. Er scheitert an einem Reflex.
Wenn ein Fehler passiert, ist die schnellste Reaktion: Im Chat korrigieren, weitermachen, Aufgabe abschliessen. Nicht zurückgehen und eine Konfigurationsdatei öffnen. Nicht überlegen, wohin das Feedback gehört. Nicht aufschreiben.
Kennen wir selbst zu gut.
Die Investition von zwei Minuten nach einem Fehler zahlt sich schnell aus. Aber nur, wenn man sie wirklich macht. Nicht im Kopf behält. Aufschreibt. Irgendwo ablegt, wo es beim nächsten Mal wieder verfügbar ist.
«Mentale Notizen» überleben keine Session-Neustarts. Dateien schon. 😉
Key Takeaways
- Der Lernloop ist kein sechster Baustein, er ist die Schicht die alle anderen über Zeit besser macht
- Feedback im Chat verpufft. Feedback im System bleibt
- Fünf Zielorte für fünf Typen von Feedback: Identität, Gedächtnis, Skills, Schnittstellen, Governance
- Du brauchst kein komplexes Setup, du brauchst eine Stelle, wo Korrekturen ankommen und bleiben
- Der Unterschied zwischen KI-Nutzern und KI-Teams: Lernt das System mit?
Fazit
Mit dieser Ausgabe schliessen wir die KI-Betriebssystem-Serie ab.
Wir haben gemeinsam aufgebaut, was ein KI-Betriebssystem braucht, das wirklich Arbeit erledigt: Identität, Gedächtnis, Skills, Schnittstellen, Governance. Und jetzt den Lernloop als die Schicht, die alles über Zeit schärft.
Das Ziel war nie, ein perfektes System vom ersten Tag an zu bauen. Das gibt es nicht. Das Ziel ist es, ein System zu bauen, das mit jedem Durchlauf ein bisschen verlässlicher wird.
Bis nächsten Sonntag 👋🏽
Andreas

Kommentare
Melde dich an, um einen Kommentar zu schreiben.