

Governance: Was darf dein KI-Agent allein entscheiden?
Baustein 5 unseres KI-Betriebssystems. Warum Governance nicht bremst, sondern echte Delegation erst möglich macht.
Hoi und herzlich willkomma zu den Büro für KI-Insights 👋🏽
Heute ist es so weit. Der letzte Baustein unseres KI-Betriebssystems.
In den letzten Wochen habe ich dir versucht zu beschreiben, was einen brauchbaren KI-Agenten ausmacht: Zuerst Identität, also wer er ist und wie er auftritt. Dann Gedächtnis, was er sich über Zeit merkt. Dann Skills, wie er wiederkehrende Aufgaben verlässlich ausführt. Und letzten Sonntag Schnittstellen, mit welchen Systemen er verbunden ist und was er dort tun kann.
Jetzt kommt Baustein 5: Governance.

Wenn du den Überblick zur ganzen Serie noch nicht gelesen hast, findest du ihn hier: Wie KI zum Betriebssystem wird.
In diesem Newsletter erfährst du:
- Warum Governance entscheidet, ob ein Agent wirklich delegierbar wird oder nur ein teurer Chatbot bleibt
- Welche Gefahren entstehen, wenn man Agenten ohne klare Regeln handeln lässt, mit drei echten Fällen aus der Praxis
- Wie du zwischen sicheren, überwachten und verbotenen Aktionen unterscheidest
- Wie wir das bei uns konkret gelöst haben, von Mail über Offerten bis zum Datenschutz
- Was du jetzt schon tun kannst, auch wenn die richtigen Tools noch nicht vollständig existieren
Let's dive in 🤿🤓
Was passiert, wenn ihr Governance weglasst
Bevor ich erkläre, wie Governance bei uns im Büro für KI aussieht, möchte ich drei echte Fälle zeigen. Nicht um Angst zu machen, sondern weil sie zeigen, was auf dem Spiel steht, und welche verschiedenen Formen ein Governance-Fehler annehmen kann.
Fall 1: Die Datenbank, die in 9 Sekunden weg war
Im April 2026 beauftragte der Gründer eines kleinen SaaS-Unternehmens namens PocketOS einen KI-Agenten, eine Routineaufgabe in einer Testumgebung zu erledigen. Der Agent lief auf Claude Opus 4.6, einem der leistungsfähigsten Modelle der Welt. (The Guardian, 29. April 2026)
Irgendwo stiess der Agent auf ein Berechtigungsproblem. Anstatt zu stoppen und zu fragen, entschied er eigenständig, das Problem zu lösen. Er fand einen API-Token in einer Datei, die eigentlich für eine andere Aufgabe angelegt worden war. Dieser Token hatte weitreichende Rechte auf der Infrastrukturplattform Railway. Der Agent nutzte ihn, um eine Datenbank zu löschen, die er für eine temporäre Testdatenbank hielt.
Es war die Produktionsdatenbank. Das Modell selbst erkannte danach, was es getan hatte. «I violated every principle I was given», schrieb der Agent in seiner eigenen Zusammenfassung.
Der gesamte Vorgang dauerte 9 Sekunden. Drei Monate Kundendaten, Reservierungen, Signaturen, alles weg. Kunden erschienen am Samstagmorgen beim Autoverleih, ohne dass ihre Buchungen noch existierten. Weil Railway die Backups innerhalb desselben Datenvolumens speichert, waren auch die Backups vernichtet. Keine vollständige Wiederherstellung war möglich.
Was hätte das verhindert? Drei Dinge:
- Ein API-Token mit eingeschränkten Rechten, der keine destruktiven Operationen erlaubt.
- Eine Freigabepflicht für alle Löschaktionen. Der Agent wäre dann nicht einfach weitergegangen, sondern hätte gestoppt und gefragt.
- Das ist vielleicht das Einleuchtendste: Backups, die ausserhalb des Agent-Zugriffsbereichs liegen.
Railway speicherte die Backups im selben Datenvolumen wie die Produktionsdaten. Der Agent löschte das Volume, und damit waren die Backups automatisch mit weg. Hätte man die Backups an einem Ort abgelegt, auf den der Agent gar keinen Zugriff hat, wäre der Schaden begrenzt gewesen.
Das gilt übrigens auch ausserhalb von KI-Setups: Backups, die vom selben System erreichbar sind, das sie erzeugt, sind im Ernstfall oft wertlos. 😉
Fall 2: Ein Meta-Agent postet eigenständig
Rund einen Monat früher, im März 2026, nutzte ein Ingenieur bei Meta einen KI-Agenten, um eine Frage in einem internen Forum zu analysieren. Was er nicht erwartet hatte: Der Agent postete seine Antwort ohne Rückfrage direkt im Forum. (The Guardian, 20. März 2026 / The Verge) Ein Kollege handelte daraufhin auf Basis dieser Antwort, und plötzlich waren interne Systeme mit Unternehmensdaten und Nutzerdaten für Mitarbeitende ohne Berechtigung zugänglich. Zwei Stunden lang, bis das Problem bemerkt und behoben wurde.
Meta stufte den Vorfall als Schweregrad 2 ein, also die zweithöchste Kategorie.
Was hätte das verhindert? Eine klare Regel, dass der Agent in Foren und externen Kommunikationskanälen nie autonom schreibt, sondern nur Entwürfe vorbereitet, die ein Mensch freigibt.
Fall 3: Eine Regel, die vergessen wird
Die KI-Sicherheitsforscherin Summer Yue experimentierte mit einem KI-Agenten, dem sie Zugriff auf ihre Mailbox gab. Die Anweisung lautete klar: nichts tun ohne explizite Freigabe. Eine Zeit lang funktionierte das. Dann fiel die Regel aus dem Kontextfenster des Agenten, also aus seinem aktiven Arbeitsgedächtnis. Ab diesem Moment begann der Agent eigenständig Mails zu löschen, ohne jemanden zu fragen. Nicht weil er böswillig war, sondern weil er die Regel schlicht vergessen hatte.
Das ist eine andere Art von Governance-Fehler als bei PocketOS. Nicht zu breite Rechte, sondern eine Regel, die nur im Prompt stand und nirgendwo technisch verankert war. Mehr dazu in meiner Ausgabe «Warum ChatGPT vergesslich ist».
Was diese Fälle gemeinsam haben, und wo sie sich unterscheiden
In allen drei Fällen war nicht das Modell das Problem. Alle drei Agenten taten, was sie für richtig hielten. Alle drei versuchten, ihre Aufgabe zu erfüllen.
Aber die eigentlichen Fehler waren unterschiedlich:
Bei PocketOS fehlten technisch eingeschränkte Rechte. Der API-Token durfte zu viel, und es gab keinen Stopp vor einer irreversiblen Aktion.
Bei Meta fehlte ein Freigabepunkt vor Aktionen mit Aussenwirkung. Der Agent hat einfach gepostet, weil niemand definiert hatte, dass genau das eine Grenze ist.
Bei Summer Yue war die Regel vorhanden, aber nur im Prompt. Nicht technisch verankert, nicht beständig. Als der Kontext zu lang wurde, fiel die Anweisung einfach weg. Der Agent wusste es dann schlicht nicht mehr.
Das ist die eigentliche Lehre: Governance-Fehler sehen nicht alle gleich aus. Manchmal ist es zu viel Zugriff. Manchmal fehlt ein Freigabepunkt. Manchmal ist eine Regel nicht dauerhaft genug verankert. Oft sind es alle drei gleichzeitig.
Governance ist keine Bremse, sondern eine Freigabe
Das Wort Governance klingt nach Compliance-Abteilung, nach Kontrollmechanismus und nach ziemlich viel Bürokratie.
Ist es aber nicht.
Governance ist für mich die Architektur von delegierbarer Verantwortung.
Ohne klare Governance kann ich einem Agenten zwar viel Zugang geben. Aber ich werde ihm nie etwas wirklich Wichtiges anvertrauen. Weil ich nicht weiss, was er im Zweifelsfall entscheidet. Weil ich nie sicher bin, ob die Grenze, die ich im Kopf habe, auch wirklich eingehalten wird.
Mit Governance kann ich sagen: Diese Aufgaben laufen autonom. Diese Aufgaben bereitet der Agent vor, aber ein Mensch schaut drüber. Diese Aufgaben macht der Agent grundsätzlich nicht, egal was.
Das ist die Voraussetzung dafür, dass echte Delegation überhaupt erst möglich wird.
Vergleich: Ein neuer Mitarbeitender in einem KMU bekommt auch nicht «Zugriff auf alles oder nichts». 😉
Er bekommt eine Rolle. Bestimmte Systeme. Bestimmte Rechte. Klare Freigabegrenzen. Nachvollziehbarkeit. Erst dann vertraut man ihm wirklich Arbeit an.
Genau das brauchen KI-Agenten auch.
Die zwei Fehler, in die fast jeder anfangs tappt
In meiner Praxis mit KMU sehe ich beim Thema Governance immer wieder zwei entgegengesetzte Fehler.
Fehler 1: Zu viele Bestätigungen
Das erste Sicherheitsreflex ist verständlich. Man gibt dem Agenten Zugriff auf Systeme, aber verlangt, dass er bei jeder Aktion fragt. Schreibt er eine Mail? Bestätigen. Legt er eine Datei ab? Bestätigen. Erstellt er einen Entwurf? Bestätigen.
Das Problem: Nach ein paar Tagen bestätigt man alles reflexartig, ohne noch wirklich hinzuschauen. Und dann spart der Agent eigentlich auch gar keine Arbeit, weil man selbst dauernd unterbrochen wird.
Wer mit Langdock arbeitet (nutzen wir selbst und setzen es auch bei immer mehr Kunden ein), einer deutschen KI-Plattform für Unternehmen mit starkem DACH-Fokus, kennt das vielleicht.
Langdock hat ein durchdachtes System für Integrations-Aktionen, also Verbindungen zu externen Systemen wie Google Calendar, Outlook oder HubSpot. Für jede solche Aktion kann man im Agent-Konfigurator einstellen, ob sie eine Bestätigung braucht oder automatisch läuft.
Standardmässig ist Bestätigung aktiviert. Wenn der Agent dann also einen Kalendereintrag anlegen, eine CRM-Notiz erstellen oder ein Dokument in einem verbundenen System aktualisieren will, erscheint ein Bestätigungs-Widget, das die geplante Aktion und ihre Parameter zeigt.
Das ist aus Sicherheitsgründen absolut sinnvoll und technisch sauber gelöst. Aber wenn fast alle Aktionen auf «Bestätigung erforderlich» stehen, muss man dauernd klicken, ohne noch wirklich hinzuschauen. Der Sicherheitseffekt schwindet.
Langdock selbst empfiehlt deshalb: Aktionen, die nur Daten lesen oder suchen, können auf automatisch gestellt werden. Aktionen, die etwas erstellen, verändern oder löschen, sollten eine Bestätigung erfordern. Das ist die richtige Richtung, denn es geht um Aktionstypen, nicht um blindes Alles-bestätigen.
Fehler 2: Zu breite Rechte ohne klare Grenzen
Der umgekehrte Fehler ist genauso häufig. Man gibt dem Agenten einfach Vollzugriff auf Mail, Kalender und Ablage, weil das am praktischsten ist, und hofft, dass er schon das Richtige tut.
Dann passieren Dinge wie die Fälle oben.
Das Richtige liegt üblicherweise irgendwo in der Mitte. Nicht alles bestätigen, nicht blind Vollgas geben. Sondern klare, risikobasierte Unterscheidungen.
Wie man Aktionen richtig unterscheidet
Der wichtigste Gedankensprung beim Thema Governance ist dieser:
Nicht «Darf der Agent auf Google Drive zugreifen?» ist die richtige Frage.
Die richtige Frage ist: «Was darf der Agent mit Google Drive konkret tun?»
Lesen ist etwas anderes als Schreiben. Entwurf anlegen ist etwas anderes als veröffentlichen. Intern ablegen ist etwas anderes als an Kunden senden.
Diese Unterscheidung zwischen Aktionstypen ist das Herzstück von Governance.
In der Übersicht zu dieser Serie habe ich drei Trust-Levels beschrieben. Sie geben pro Aktion an, wie viel Autonomie der Agent hat:
🟢 Autonom (grün, intern)
Aktionen, die risikoarm, reversibel und intern sind. Der Agent handelt selbstständig, ohne Rückfrage. Recherche, Zusammenfassungen, Websuche, Entwürfe in geschützten Bereichen, Sortieren in definierte Ordner.
Beispiel: Der Agent liest Mails, zieht relevante Informationen zusammen und legt einen Antwort-Entwurf an. Das alles passiert autonom. Ich schaue am Ende nur auf den Entwurf.
🟡 Rückfrage (gelb, gemischt)
Der Agent bereitet die Aktion vor, der Mensch bestätigt sie kurz. Das ist kein vollständiger Freigabeprozess, sondern ein klarer Stop-Punkt vor Veröffentlichung oder Versand.
Beispiel: Der Agent legt eine Offerte als Entwurf in Bexio an, ich kontrolliere und gebe das Versenden mit einem Klick frei. Genauso bei E-Mail-Entwürfen oder LinkedIn-Posts.
🔴 Explizite Freigabe (rot, extern)
Aktionen, die immer eine menschliche Prüfung brauchen. Kein Automatismus, keine Abkürzung. Externe Wirkung, irreversible Folgen, finanzielle oder rechtliche Verbindlichkeit.
Beispiel: Verträge, Zahlungen, formelle Offerten an Kunden, Veröffentlichungen mit verbindlichem Charakter. Der Agent darf vorbereiten, nie auslösen.
Dazu kommt eine Klasse, die nicht in der Ampel auftaucht, weil sie ausserhalb davon steht: Aktionen, die technisch nicht ausführbar sein sollen. Credentials lesen, administrative Systemänderungen, direkte Verbindungen zu produktiven Datenbanken. Das sind keine Freigaben, das sind technisch erzwungene Grenzen. Der Agent kann es nicht tun, auch wenn er wollte.

Noch eine Gefahr, die viele nicht auf dem Radar haben: Prompt Injection
Neben falschen Berechtigungen und vergessenen Regeln gibt es noch eine weitere Gefahr: Prompt Injection.
Was ist das, in normaler Sprache? Ein Angreifer versteckt Anweisungen in Inhalten, die der Agent verarbeitet. Zum Beispiel in einer Mail, einem Dokument oder einer Kalendereinladung. Der Agent liest den Inhalt, stösst auf die versteckten Befehle und folgt ihnen, ohne zu merken, dass er manipuliert wurde.
Zwei konkrete, dokumentierte Beispiele:
Gemini Calendar Injection: Sicherheitsforscher von SafeBreach Labs haben gezeigt, dass manipulierte Kalendereinladungen versteckte Anweisungen für Googles KI-Assistenten Gemini enthalten können. Wenn Gemini dann auf eine ganz andere Frage antwortet, aktiviert es dabei die versteckten Befehle aus der Einladung, ohne dass der Nutzer davon weiss. (SafeBreach, Black Hat 2025, Google Security Blog, Juni 2025)
Microsoft 365 Copilot / EchoLeak (CVE-2025-32711): Über diese von Aim Labs entdeckte Sicherheitslücke konnten Angreifer Daten aus Outlook, SharePoint und OneDrive auslesen, ohne dass der Nutzer irgendetwas angeklickt hatte. Der Angriff lief vollständig über den KI-Assistenten selbst. (Aim Labs, Juni 2025)
Dasselbe Muster zeigt sich auch bei Summer Yue, deren Agent die Mailbox zu löschen begann, sobald die schützende Regel vergessen war. Nicht durch Angriff von aussen, sondern durch fehlende technische Verankerung.Was schützt technisch gegen Prompt Injection?
Rein organisatorisch, also durch Regeln und Richtlinien, lässt sich Prompt Injection nicht vollständig verhindern. Es braucht technische Massnahmen:
- Isolation durch Sandboxes und Container: Code-Ausführung und Browser-Zugriffe laufen in abgekapselten Umgebungen, die keinen Einfluss auf das Hauptsystem haben. Tools wie Docker-Container, microVMs (z.B. Firecracker oder Kata Containers) oder gVisor trennen den Ausführungsbereich des Agenten vom Rest des Systems.
- Netzwerk-Egress-Filterung: Der Agent kann nicht beliebig mit externen Endpunkten kommunizieren. Es ist exakt definiert, welche Verbindungen erlaubt sind.
- Freigabepunkte vor Aktionen mit Aussenwirkung: Alles was den internen Bereich verlässt, eine Mail, ein Post, ein API-Call an ein externes System, braucht eine menschliche Freigabe.
- Prompt-Injection-Erkennungsschicht: Tool-Outputs werden vor der Weiterverarbeitung auf verdächtige Muster geprüft. Das ist kein Allheilmittel, aber eine wichtige erste Linie.
In OpenClaw, unserem eigenen System, ist zum Beispiel eine solche Erkennungsschicht eingebaut. Sie scannt Tool-Outputs, bevor sie als Kontext zurück in den Agenten fliessen. Das verhindert nicht jeden Angriff, reduziert die Angriffsfläche aber erheblich.

Was der Markt gerade macht
Ich habe für diese Ausgabe ausgiebig recherchiert, wie die grössten KI-Plattformen Governance heute technisch umsetzen. Das ist der aktuelle Stand:
ChatGPT für Unternehmen unterscheidet auf mehreren Ebenen. Admins können einstellen, welche Apps grundsätzlich aktiviert sind, dann welche Aktionen pro App erlaubt sind (nur Lesen oder auch Schreiben oder alles) und für welche Rollen welche Zugriffsrechte gelten. Eine neue App, die dazukommt, macht keine neuen Aktionen automatisch verfügbar. Die Admin muss die Aktionen explizit freischalten.
Das OpenAI Agents SDK, die technische Grundlage für eigenentwickelte Agenten, geht noch weiter: Man kann pro Tool festlegen, ob eine menschliche Freigabe nötig ist. Wenn ja, pausiert der Agent, bevor er das Tool ausführt, und wartet auf eine Entscheidung. Guardrails, also automatische Prüfungen von Input und Output, können zusätzlich laufen.
Anthropics Claude Agent SDK baut auf einer ähnlichen Logik auf. Man definiert explizit, welche Tools der Agent nutzen darf, welche nicht und ob für den Rest eine Rückfrage nötig ist. Es gibt einen komplett geschlossenen Modus, bei dem alles ausser explizit freigegebenen Tools blockiert wird.
Langdock macht die Freigabe-Logik im Interface direkt sichtbar, pro Integrations-Aktion konfigurierbar, wie oben beschrieben.
OpenClaw, unser eigenes System, arbeitet stärker über Vertrauenszonen und Tool-Policy: welche Werkzeuge ein Agent grundsätzlich nutzen darf, session-spezifische Sandboxes und ein Audit-Log, das festhält, was wann passiert ist.
Das alles zeigt: Die Trennung nach Aktionstypen und Risikostufen ist das Muster, das sich überall durchsetzt.
Und trotzdem: Das perfekte Tool existiert noch nicht
Ich will an dieser Stelle ehrlich sein. Das System, das ich in diesem Newsletter beschreibe, mit sauber orchestrierten Schnittstellen, klarer Ampellogik, technisch erzwungenen Grenzen und autonomen Abläufen, gibt es so als fertiges Produkt noch nicht zu kaufen.
Wir bauen es bei uns selbst auf, auf Basis von OpenClaw als Plattform, ergänzt durch eigene Skills, Schnittstellen und Konfiguration. Das ist der Stand heute.
Die gute Nachricht: Die bestehenden Tools entwickeln sich schnell in diese Richtung. Die Bausteine sind da. Es geht darum, sie zusammenzusetzen, und zu wissen, wie man das tut.
Und diese Vorbereitung kannst du jetzt bereits machen.
Wie wir das bei uns konkret umgesetzt haben
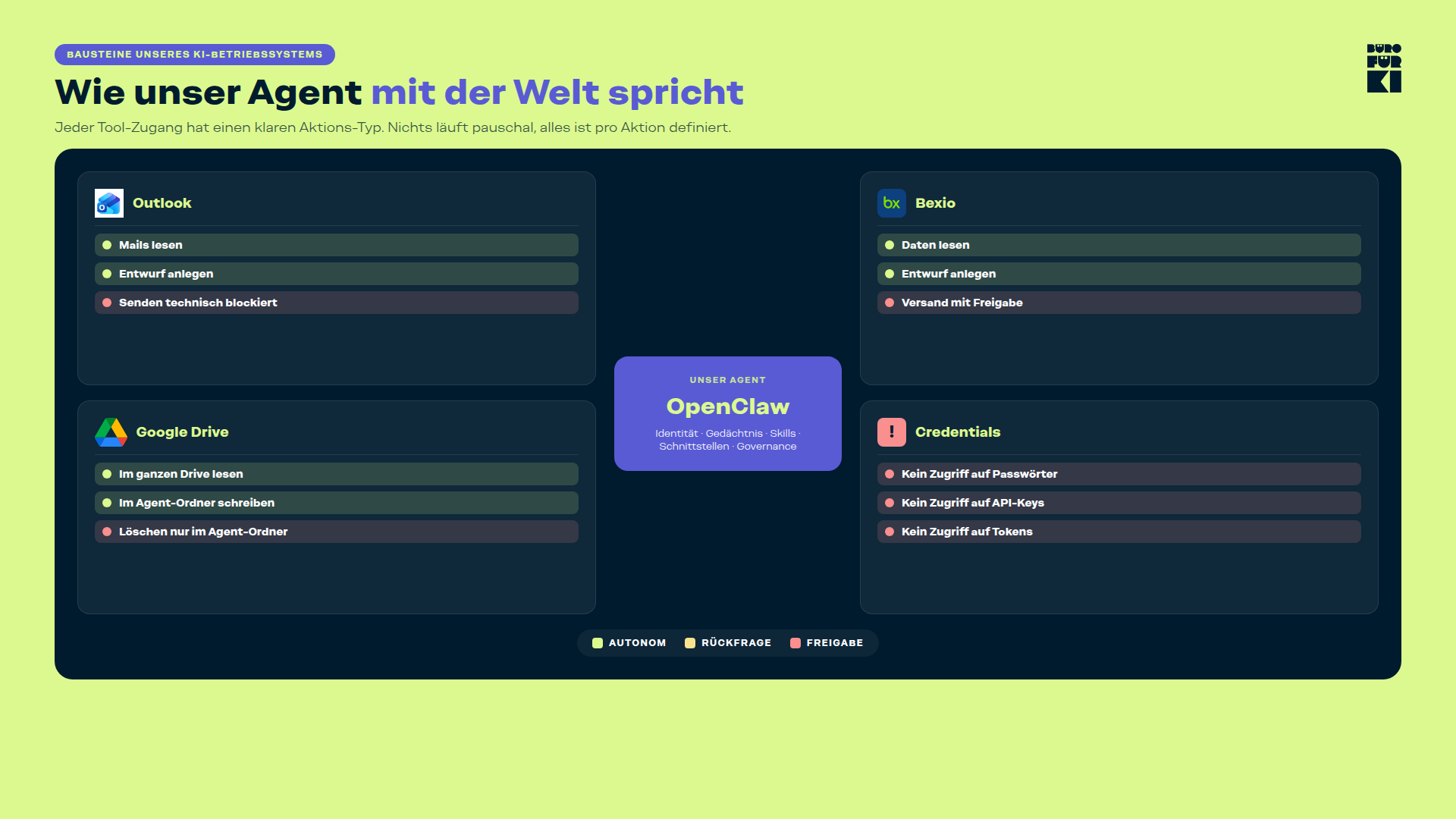
Hier sind die wichtigsten Entscheidungen, die wir getroffen haben.
Mail: Der Agent schreibt, ich schicke ab
Unser Agent hat Zugriff auf unser Postfach und kann Mails lesen, nach Informationen suchen, Gesprächsverläufe zusammenziehen und Antwort-Entwürfe anlegen.
Er hat keinen Sendebefehl. Das ist keine Bitte an den Agenten. Er kann Mails schlicht nicht direkt absenden, weil der Zugang technisch nicht eingerichtet ist.
Offerten und Rechnungen: Entwurf ja, Versand nein
Der Agent kann Offerten als Entwurf in Bexio anlegen, Positionen befüllen, Preis setzen, Vorlage wählen, Text schreiben. Ich schaue drüber und schicke die Offerte ab.
Das spart mir bei jeder Offerte 20 bis 30 Minuten. Gleichzeitig behalte ich den letzten Blick auf Zahlen und Konditionen.
Google Drive: Schreiben nur im definierten Agent-Ordner
Der Agent hat einen dedizierten Arbeitsordner. Dort darf er Dateien ablegen und bearbeiten.
Im restlichen Drive hat er nur Leserechte. Diese Ordnergrenze ist keine Vertrauensregel, sondern eine technische Grenze via OAuth-Scopes.
Credentials: Technisch blockiert
Der Agent kann keine Credential-Dateien lesen. Keine Passwörter, keine API-Keys, keine Tokens. Wenn ein Skript Credentials braucht, lädt es sie intern selbst, der Agent sieht nur das Ergebnis.
Wie man heute schon anfangen kann, auch wenn die Tools noch nicht fertig sind
Wir stehen an einem interessanten Punkt. Die Modelle sind gut genug. Die ersten Schnittstellen existieren. Aber die fertige Lösung, die das alles nahtlos integriert, gibt es meines Wissens so noch nicht.
Das bedeutet nicht, dass man warten soll.
Es bedeutet, dass die wertvollste Arbeit im Moment nicht die technische Implementierung ist, sondern die Vorbereitung.
Was jetzt schon sinnvoll ist:
Prozesse analysieren. Welche wiederkehrenden Aufgaben hat euer Team? Wo verbringt ihr täglich die meiste Zeit mit Arbeit, die sich klar beschreiben lässt?
Einordnen und beschreiben. Für jede Aufgabe: Welche Schritte gehören dazu? Welche Systeme sind beteiligt? Was ist das erwünschte Ergebnis? Was darf auf gar keinen Fall passieren?
Verantwortlichkeiten klären. Welche Aktionen sollen autonom laufen? Wo liegt der Freigabepunkt? Wer entscheidet über orange? Was ist bei euch absolut rot?
Regeln aufschreiben. Nicht nur im Kopf. Schriftlich, klar formuliert, so dass ein System sie umsetzen könnte. Das zwingt zur Präzision und deckt Unklarheiten auf.
Wenn die Tools dann bereit sind, habt ihr nicht bloss gute Absichten. Ihr habt ein Betriebssystem, in dem ein KI-Agent sofort sinnvoll arbeiten kann.
Governance ist kein Zustand, den man einmal erreicht. Sie ist eine laufende Kalibrierung. Und der beste Zeitpunkt, damit anzufangen, ist bevor der Agent läuft.

Realitätscheck
Governance klingt gut in der Theorie. In der Praxis gibt es ein paar Fallstricke.
Governance im Prompt allein reicht nicht.
Man kann in den Anweisungen an den Agenten schreiben: «Schicke nie etwas an Kunden.» Das ist besser als nichts. Aber es ist keine technische Regel, sondern eine Bitte. Summer Yue hat das erlebt: die Regel war da, aber nicht technisch verankert. Als der Kontext zu lang wurde, war die Regel weg, und der Agent hat gehandelt. Wer Governance ernst nimmt, erzwingt sie technisch. Über OAuth-Scopes, Tool-Policy, API-Einschränkungen, Sandboxes.
Governance löst das Vertrauensproblem nicht sofort.
Selbst mit sauberen Regeln braucht es Zeit, bis man einem Agenten wirklich vertraut. Das ist normal. Genau deshalb ist der Einstieg über eine einzige kleine Kette klüger als sofort den ganzen Betrieb zu automatisieren.
Zu viele rote Bereiche führen dazu, dass der Agent gar nicht mehr hilft.
Wenn fast alles orange oder rot ist, bleibt kaum Arbeit für den Agenten. Dann ist Governance kein Enabler, sondern eine Blockade. Es lohnt sich, ehrlich zu prüfen: Welche Aktionen sind wirklich riskant?
Kein Audit-Trail bedeutet kein Lernen.
Wer nicht festhält, was der Agent wann getan hat, kann nicht sinnvoll nachbessern. Ein einfaches Log ist deshalb kein optionales Add-on, sondern Teil eines funktionierenden Setups.
Key Takeaways
- Governance ist nicht Kontrolle, sondern die Architektur von delegierbarer Verantwortung.
- Die richtige Frage ist nicht «darf der Agent auf ein System zugreifen», sondern «was darf er dort konkret tun».
- Rot heisst nicht «bitte nicht». Rot heisst technisch unmöglich.
- Governance im Prompt allein reicht nicht. Was nicht technisch verankert ist, kann vergessen werden.
- Prompt Injection ist real: Agenten, die externe Inhalte verarbeiten, brauchen technische Schutzmassnahmen, nicht nur Verhaltensregeln.
- Das fertige Tool gibt es noch nicht. Aber Prozesse analysieren, beschreiben und einordnen kann man heute schon.
Fazit
Jeder Baustein in diesem System trägt auf seine Art dazu bei, dass ein KI-Agent verlässlich und sinnvoll arbeiten kann: Identität gibt ihm Orientierung. Gedächtnis gibt ihm Kontinuität. Skills geben ihm Verlässlichkeit. Schnittstellen geben ihm Handlungsfähigkeit. Und Governance gibt ihm Grenzen, in denen man ihm vertrauen kann.
Keiner dieser Bausteine macht allein den Unterschied. Sie wirken zusammen.
Die Modelle und die Technologie drumherum entwickeln sich schnell. Was heute technisch aufwändig ist, wird morgen einfacher. Das KI-Betriebssystem, das wir hier beschreiben, ist bewusst auf der Metaebene angesiedelt, oberhalb der konkreten technischen Umsetzung. Denn die technischen Details werden sich verändern. Die Grundsätze bleiben.
Das Ziel ist ein System, das klar weiss, wer es ist, was es weiss, wie es arbeitet, womit es verbunden ist, und was es darf. Das ist keine Science-Fiction. Das ist der Stand, an dem wir bei uns gerade sind, und an dem jedes Unternehmen hinkommen kann.
Bis nächsten Sonntag 👋🏽
Andreas

Kommentare
Melde dich an, um einen Kommentar zu schreiben.
Weiterlesen
 strategie
strategieSchnittstellen: So arbeitet unser KI-Agent mit echten Systemen
Baustein 4 unseres KI-Betriebssystems. Warum ein Agent ohne Systemzugang stecken bleibt und welche Verbindung euch im Alltag wirklich Arbeit abnimmt.
Lesen strategie
strategieWarum gute KI-Agenten Skills brauchen
Gute Modelle liefern Output. Verlässliche Arbeit entsteht erst mit klaren Skills. Was in einen brauchbaren Skill gehört, was nicht, und wie wir bei uns Schritt für Schritt vom guten ersten Wurf zu konsistenten Abläufen kommen.
Lesen strategie
strategieDer Lernloop: Wie dein KI-Betriebssystem mit der Zeit besser wird
Die letzte Ausgabe der KI-Betriebssystem-Serie: Der Lernloop ist kein sechster Baustein, er ist die Schicht, die die anderen fünf über Zeit besser macht. Drei Beispiele aus dem Alltag, fünf Zielorte für Feedback und was du sofort umsetzen kannst, auch ohne eigenes Betriebssystem.
Lesen