
Was weiss deine KI eigentlich?
Was weiss er? Wie KI-Agenten ein digitales Gedächtnis bekommen
Hoi und herzlich willkomma zu den Büro für KI-Insights 👋🏽
In den Grundlagen unserer Workshops erkläre ich immer, wie ein Sprachmodell eigentlich funktioniert. Dass es auf riesigen Textmengen trainiert wurde, dass daraus Gewichte entstehen, und dass diese Gewichte ab dem Deployment eingefroren sind. Das Modell lernt nicht in Echtzeit dazu, egal wie oft du es benutzt.
An dieser Stelle meldet sich fast immer jemand. «Aber ich habe das Gefühl, das lernt ja irgendwie doch dazu. ChatGPT merkt sich doch, dass ich keine ß im Text lesen will, oder dass ich weniger Gedankenstriche mag.»
Verständliche Reaktion, das Verhalten sieht eben wirklich so aus, als würde das Ding lernen. In Wahrheit läuft etwas anderes im Hintergrund ab, und genau darum geht es heute.
Die umgekehrte Erfahrung kennt aber auch jede Person, die regelmässig mit KI arbeitet. Man gibt zum dritten Mal denselben Kontext ein, erklärt nochmal, für welchen Kunden man gerade schreibt, was letzte Woche vereinbart wurde, wer im Projektteam ist und welche Eckdaten das Angebot hat. Irgendwann nervt das. Nicht weil man selbst vergesslich wäre, sondern weil das Werkzeug schlicht kein Gedächtnis hat.
Letzte Woche ging es um den ersten Baustein unseres KI-Betriebssystems, die Identität. Heute ist Gedächtnis dran. Baustein 2 von 5 unseres agentischen Systems im Büro für KI.

Identität und Gedächtnis sind das Sein des Agenten. Wer er ist und was er weiss. In den nächsten Ausgaben folgen Skills und Schnittstellen (das Tun) und Governance (das Dürfen). Wer den Überblick über die fünf Bausteine noch nicht gelesen hat, findet ihn hier.
In diesem Newsletter erfährst du:
- Warum das Sprachmodell selbst nichts dazulernt und was das in der Praxis bedeutet
- Welche vier Schichten ein brauchbares Agent-Gedächtnis braucht
- Was passiert, wenn Agenten anfangen zu «träumen»
- Was nicht ins Gedächtnis gehört, obwohl es oft dort landet
- Warum der häufigste Framework-Default mich am Anfang ziemlich viel Geld gekostet hat
Let's dive in 🤓🤿
Die Frage
Baustein 2 lässt sich auf drei Wörter reduzieren. Was weiss er?
Bei uns Menschen ist das in der Praxis einigermassen trivial. Ich bin inzwischen 40 und kann mich an Dinge aus meiner Kindheit erinnern. Nicht an alles, aber an das Wesentliche. Das Gehirn sortiert aus, vergisst Unwichtiges, behält Entscheidendes. Wir müssen nicht aktiv daran denken, unsere Erinnerungen aufzurufen, sie sind einfach da, wenn wir sie brauchen.
Bei einem KI-Agenten funktioniert das aber fundamental anders. Sein Wissen muss ihm bei jeder einzelnen Aufgabe neu mitgegeben werden, aktiv, bewusst, in der richtigen Dosis. Wer das nicht versteht, baut ein System, das jeden Morgen bei null anfängt. Wie wichtig der passende Kontext für gute Antworten ist, habe ich in einer früheren Ausgabe bereits angerissen.
Modell, Kontextfenster und externes Gedächtnis
Eigentlich braucht es dafür gar keine grosse Analogie. Man kann es relativ direkt erklären. Ich versuch's so einfach wie möglich.
Ein Agent besteht in diesem Zusammenhang aus drei Ebenen:
- Dem Modell selbst. Das ist trainiert, danach eingefroren und lernt im Alltag nicht einfach weiter. Eine neue Version gibt's erst, wenn z. B. bei OpenAI ein neues trainiert wurde (z. B. GPT-5.5 usw.)
- Dem Kontextfenster. Das ist alles, was bei einer konkreten Anfrage gerade mitgeschickt wird. Systemhinweise, aktuelle Projektinfos, Memory-Ausschnitte, Nutzerwunsch, vorherige Nachrichten.
- Dem externen Gedächtnis. Dort liegt viel mehr Wissen, als gleichzeitig ins Kontextfenster passt.

Wir starten von hinten, bei Ebene 3, dem Modell. Das Modell ist das Hirn. Es kann Sprache verarbeiten, Muster erkennen und generalisieren. Aber es erinnert sich nicht einfach an dein Projekt, nur weil ihr gestern schon einmal darüber gesprochen habt.
Ebene 2: Das Kontextfenster ist der aktuelle Arbeitskontext. Nur damit kann das Modell in diesem Moment arbeiten. Alles, was nicht im Kontextfenster landet, existiert für diese Anfrage praktisch nicht.
Und genau darum ist es in agentischen Systemen so zentral. Das Kontextfenster ist das Gefäss, das das Modell tatsächlich sieht. Auf dieser Grundlage entstehen nicht nur Antworten, sondern auch Tool-Calls, Entscheidungen und nächste Schritte.
Der Punkt ist also nicht einfach, dass das Kontextfenster begrenzt ist (in GPT-5.4 passen theoretisch 1 Million Token = ca. 750k Worte). Entscheidend ist, was darin landet. Die laufende Konversation, die aktuelle Aufgabe, relevante Memory-Ausschnitte, Instruktionen und allfällige Tool-Ergebnisse. Nur wenn diese Informationen sauber zusammengestellt sind, kann das Modell für die Aufgabe gut arbeiten.
Ebene 1: Das externe Gedächtnis ist der persistente Wissensbestand ausserhalb des Modells. Tagesnotizen, MEMORY.md, Projektdokumentation, Entscheide, Standards, Vorlieben. Bei uns ist das sehr konkret organisiert, über Dateien und Ordnerstrukturen. Dort kann viel liegen, aber nicht alles muss jedes Mal mitgeschickt werden.
Die operative Frage lautet deshalb nicht «Was weiss das Modell?», sondern «Was landet bei dieser Aufgabe im Kontextfenster?»
Wenn ich ChatGPT sage «Merke dir, dass wir in der Schweiz keine ß schreiben», dann lernt das Modell nichts. Die Gewichte, also das eigentliche neuronale Netz, verändern sich nicht. Stattdessen wird diese Information als gespeicherte Erinnerung bei späteren Anfragen wieder mitgegeben. Bei ChatGPT heisst dieser Mechanismus beispielsweise «Erinnerungen».

Lernen ist das keines. Technisch verändert sich nicht das Modell, sondern der Input. Es ist gespeichertes Wissen, das bei Bedarf wieder in den aktuellen Kontext wandert. Es wird also eurem Chat einfach mit beigefügt und somit für die Antwort berücksichtigt.
Genau daraus lässt sich ein starkes System bauen. Alles, was der Agent wissen soll, muss im richtigen Moment im Kontextfenster landen. Entweder immer, wenn es dauerhaft relevant ist. Oder gezielt dann, wenn die Aufgabe es verlangt.
Die vier Schichten eines Agent-Gedächtnisses
Normalen Chatbots wie ChatGPT oder Claude, liegt in der Regel alles immer bei. Also sowohl die ganzen Erinnerungen, als auch andere Dinge die man in ChatGPT unter Personalisierung hinterlegt hat.
Bei einem KI-Agenten muss (darf) nicht alles immer im Kontextfenster liegen. Das hat auch damit zu tun, dass ein Agent selbstständig Aktionen ausführt und wir als Mensch nicht mehr immer im Loop sind.
Ein gutes Agent-Gedächtnis arbeitet in Schichten, wir unterscheiden bei uns vier davon. Die Namen klingen vielleicht vertraut, weil sie der menschlichen Gedächtnis-Forschung entlehnt sind.
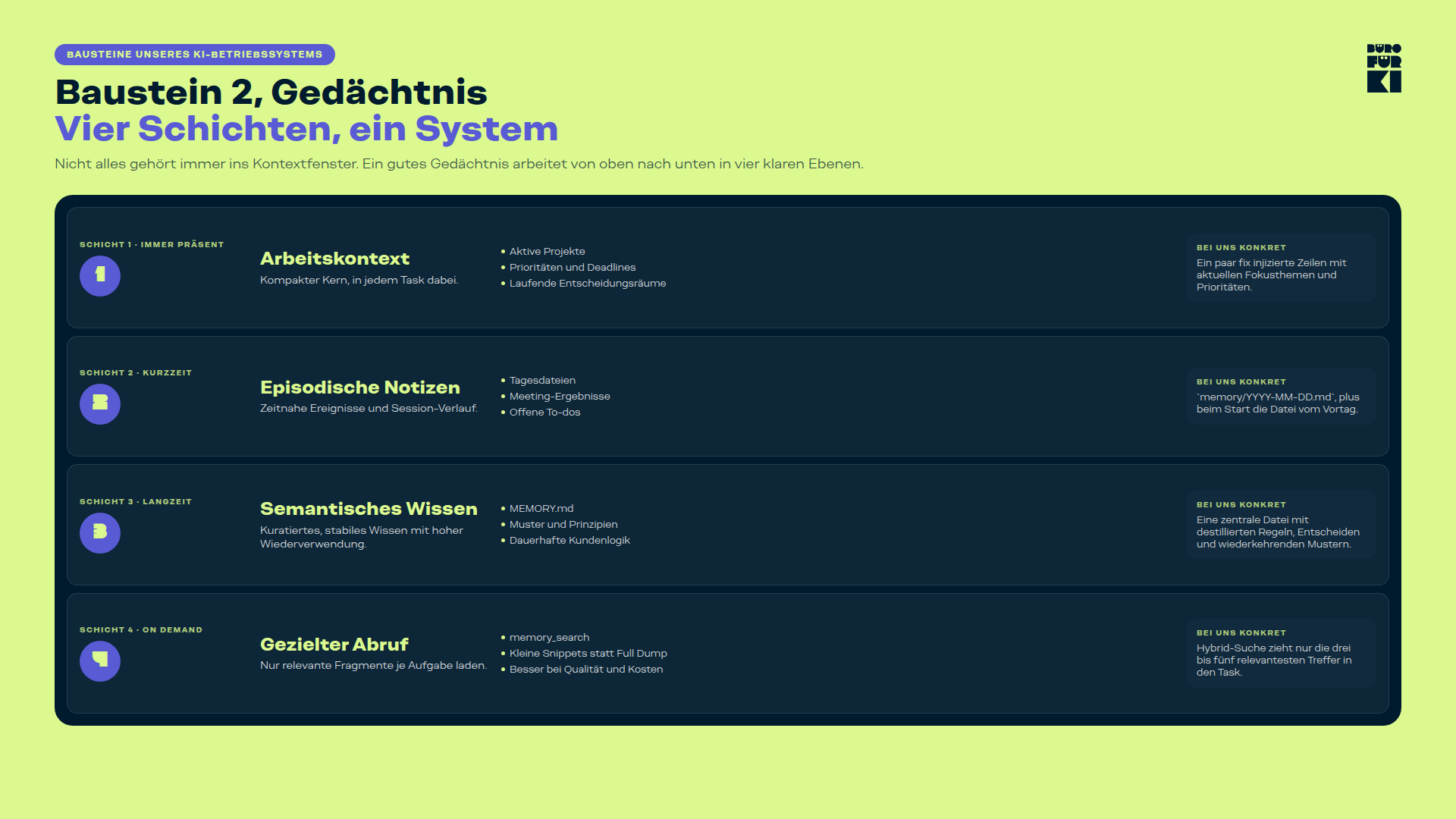
Schicht 1: Arbeitskontext (immer präsent)
Was muss der Agent in jeder Aufgabe im Kopf haben, unabhängig davon, worum es geht? Nicht wer er ist, das ist Identität (Baustein 1). Sondern was gerade in der Welt des Unternehmens gilt. Laufende Projekte, aktuelle Prioritäten, wichtige Kunden, die momentan aktiv sind, Fristen, die im Raum stehen.
Das ist das Pendant zum menschlichen Arbeitsgedächtnis. Begrenzt, immer präsent, wird ständig aktualisiert.
Schicht 2: Kurzzeit (episodisch)
Was ist kürzlich passiert? Tagesnotizen, Session-Zusammenfassungen, Entscheide der letzten Woche. Bei uns schreibt der Agent diese Einträge selbst. Nach wichtigen Arbeitssessions hält er fest, was besprochen wurde, was entschieden, was offen blieb. Nicht für mich zum Lesen, sondern für sich selbst zum Wiederfinden.
Das Pendant beim Menschen ist das episodische Gedächtnis. «Was habe ich gestern gemacht, was haben wir vor drei Wochen vereinbart». Struktur bei uns, ein Ordner memory/ mit einer Datei pro Tag (2026-04-17.md).
Schicht 3: Langzeit (semantisch)
Destillat aus Wochen und Monaten. Die grossen Entscheide, wiederkehrende Muster, wichtige Kontakte, Grundprinzipien, die sich bewährt haben. Bei uns steckt das in einer einzigen Datei, MEMORY.md. Kuratiert, verdichtet, nicht roh.
Der Unterschied zu Schicht 2: Hier stehen nicht Ereignisse, sondern Erkenntnisse. Nicht «Am 17. April haben wir über X gesprochen», sondern «Wir arbeiten bei Offerten mit Bexio immer mit Opus, weil die Qualität des Outputs viel besser ist».
Beim Menschen wäre das das semantische Gedächtnis. Was ich grundsätzlich weiss, unabhängig davon, wann ich es gelernt habe.
Schicht 4: Gezielter Abruf (on-demand)
Nicht alles kann immer im Kontextfenster liegen, sonst wird es überladen. Für alles, was tiefer in der Historie steckt oder nur manchmal gebraucht wird, brauchen wir gezielte Suche. Der Agent sucht bei Bedarf in seinem eigenen Wissensbestand und lädt nur die relevanten Stücke in den aktuellen Kontext.
Technisch ist das oft RAG (Retrieval Augmented Generation). Der Agent sucht in einem Index nach passenden Passagen und zieht nur diese ins Kontextfenster. Was dabei durchsucht wird, ist entscheidend für die Einordnung.
Wird der eigene Wissensbestand durchsucht (Memory-Files, Tagesnotizen, internes Wiki), dann ist das Gedächtnis. Geht die Suche ins Internet oder in externe Datenbanken, dann ist das eine Schnittstelle (Baustein 4 in zwei Wochen).
Beim Menschen wäre das die gezielte Erinnerungsabfrage. «Moment, was habe ich damals bei diesem Kunden wirklich notiert?». Wir sind auch nicht ständig bewusst im Kontakt mit allem, was wir wissen. Wir rufen ab.
Wenn Agenten träumen
Hier wird es interessant. In den letzten Wochen ist ein Feature in OpenClaw, dem Framework das wir nutzen, dazugekommen, das den Bogen zur menschlichen Gedächtnis-Forschung sehr explizit macht. Es heisst Dreaming, und das ist wörtlich gemeint.
Das ist aktuell noch keine generische Standardfunktion, die alle Agenten haben, sondern eine konkrete OpenClaw-Implementierung. Und auch dort erst in Beta.
Beim Menschen passiert im Schlaf etwas Bemerkenswertes. Der Hippocampus, die Hirnregion die Kurzzeit-Erlebnisse zwischenspeichert, spielt sie dem Neocortex (der äusseren Hirnrinde, unserem Langzeitspeicher) zurück. Unwichtiges wird vergessen, Wichtiges konsolidiert, Muster werden extrahiert. Wir lernen nicht so sehr während der Arbeit, sondern besonders im Schlaf.
Dreaming in einem Agent-System macht genau das. Im Hintergrund, in drei Phasen:

Light Sleep: Der Agent sortiert und gruppiert neue Signale aus den Tagesnotizen und bisherigen Recall-Traces. Dedupliziert, stapelt Kandidaten. Noch wird nichts ins Langzeitgedächtnis geschrieben.
Deep Sleep: Der Agent bewertet, welche Kandidaten ins Langzeitgedächtnis aufgenommen werden. Kriterien sind zum Beispiel, wie oft etwas in verschiedenen Kontexten aufgetaucht ist, wie relevant es war, wie gut es mit bestehendem Wissen verbunden ist. Nur was die Hürden passiert, wird in MEMORY.md geschrieben.
REM Sleep: Der Agent extrahiert Muster und Themen. «Was taucht immer wieder auf?», «Welche Entscheidungen ähneln sich?», «Welche Konflikte kehren regelmässig zurück?». Das wandert nicht direkt ins Langzeitgedächtnis, sondern verstärkt die Bewertung in der nächsten Deep-Phase.
Das System führt ausserdem ein «Dream Diary» (DREAMS.md), ein menschlich lesbares Protokoll der Konsolidierungs-Läufe, damit man nachvollziehen kann, was der Agent gelernt hat.
Ehrlich gesagt, ich experimentiere selbst noch damit. Die Technologie ist so neu, es gibt nicht die eine fertige Lösung. Wir sind mitten in einer Phase, in der das Feld noch stark in Bewegung ist. Aber die Richtung ist klar. Das Gedächtnis wird in Zukunft weniger «Datei manuell pflegen» und mehr «System beobachtet, lernt, konsolidiert». Parallel gibt es Ansätze wie Andrej Karpathys LLM Wiki, wo der Agent neue Informationen aktiv in ein strukturiertes Wiki einpflegt, statt sie nur zu indexieren. Das geht in dieselbe Richtung.
Was hier passiert, ist interessant über den technischen Aspekt hinaus. Wir bauen gerade Systeme, die grundlegende Prinzipien menschlichen Gedächtnisses nachzubauen versuchen, weil sich in der Biologie bewährt hat, dass pure Speicherung ohne Konsolidierung nicht funktioniert.
Ob das wirklich der richtige Ansatz ist wird sich zeigen. 😅
Was NICHT ins Gedächtnis gehört
So wichtig wie das, was reingehört, ist das, was draussen bleiben muss. Weil sonst Verantwortlichkeiten verschwimmen und die Wartung zum Chaos wird.
Identität ist nicht Gedächtnis. Wer der Agent ist (Werte, Stil, Grenzen) sitzt eine Ebene tiefer und wurde in der Ausgabe zum Baustein Identität behandelt. Die Identität bestimmt, wie der Agent mit Wissen umgeht, das Wissen selbst ist etwas anderes.
Skills sind nicht Gedächtnis. Wie eine Offerte erstellt wird, ist eine Fähigkeit und gehört in einen Skill (Baustein 3, nächste Woche). Dass wir eine bestimmte Struktur oder Tonalität für Offerten nutzen, gehört dort in die Skill-eigenen Referenzdaten. Dass der aktuelle Standard-Tagessatz CHF X ist, gehört ins zentrale Gedächtnis, damit er an einer Stelle gepflegt wird. Skills referenzieren das Gedächtnis, statt es zu duplizieren.
Schnittstellen sind nicht Gedächtnis. Dass der Agent Zugriff auf Google Drive hat oder eine Websuche durchführen kann, sind Schnittstellen (Baustein 4). Auch RAG über externe Quellen wie das Internet gehört hier rein, nicht ins Gedächtnis. Die Unterscheidung ist einfach. Eigenes Wissen = Gedächtnis. Zugriff auf externe Welt = Schnittstelle.
Credentials sind nicht Gedächtnis. API-Keys, Passwörter, Zugangsdaten gehören in die Governance (Baustein 5) und niemals in MEMORY.md.
Das mag nach Erbsenzählerei klingen. Bis zu dem Moment, in dem sich etwas ändert, zum Beispiel:
- Ein Preis
- Ein Prozess
- Eine Kontaktperson
Wer Gedächtnis, Skills und Schnittstellen vermischt, weiss dann nicht mehr, wo die Korrektur hingehört. Saubere Trennung erspart später viel Suchen.
Wie wir's bei uns gelöst haben
Konkret, mit Dateinamen. So sieht das Gedächtnis unseres Agenten heute ganz grob aus.
Arbeitskontext (Schicht 1): Ein paar Zeilen im fix injizierten Teil, die laufend aktualisiert werden. Aktuelle Fokusthemen, grosse laufende Projekte, dringende Prioritäten. Sehr kurz, unter 20 Zeilen, sonst ufert es aus.
Kurzzeit (Schicht 2): Ordner memory/ mit einer Datei pro Tag (2026-04-17.md). Der Agent liest beim Start der Session die Tagesdatei plus die vom Vortag und schreibt während der Arbeit neue Einträge dazu.
Langzeit (Schicht 3): Eine einzige Datei, MEMORY.md. Enthält destillierte Erkenntnisse, wiederkehrende Muster, wichtige Kundenhistorie und grundsätzliche Entscheide. Wird teils vom Agenten selbst gepflegt, teils von mir überprüft.
Gezielter Abruf (Schicht 4): Eine eingebaute Suche (memory_search) geht hybrid (Vektor plus Keyword) durch alle Memory-Dateien und zieht nur die drei bis fünf relevantesten Einträge. Wenn ich frage «was haben wir bei Kunde X vereinbart», lädt der Agent nicht alle Tagesdateien der letzten Monate, sondern findet die passende Stelle.
Neu dazu kommen die Dreaming-Läufe, die ich oben beschrieben habe, und ein DREAMS.md, das die Konsolidierungs-Summaries protokolliert. Das ist aktuell bei mir noch in der Experimentier-Phase, aber schon nach wenigen Tagen merke ich, dass das Langzeitgedächtnis auf eine andere Weise anwächst. Weniger nach meinem Gutdünken, mehr nach tatsächlicher Reinforcement-Signal-Dichte aus den Tagessessions.
Der häufigste Fehler: Einfach alles mitschicken
Als OpenClaw rauskam, habe ich es in den ersten zwei, drei Tagen einfach mal laufen lassen. Ich habe ausprobiert, rumgespielt und geschaut, was passiert. Und ziemlich schnell gemerkt, wie viel das Framework standardmässig in jedes einzelne Kontextfenster pumpt. Identität, Nutzerdaten, Tagesnotizen der letzten Tage, aktiv genutzte Skills. Alles auf einmal, bei jeder Anfrage.
Das Ergebnis waren an einem einzigen Tag mehrere hundert Franken Tokenkosten. 😅
Dieses Schicksal betrifft übrigens nicht nur OpenClaw. Jedes agentische Framework, das neu entsteht, kämpft mit derselben Frage. Was muss an den Agenten, damit er brauchbar arbeitet, und was ist Ballast? Viele Frameworks entscheiden sich zuerst für «lieber zu viel als zu wenig». Das ist verständlich, weil das Resultat meist qualitativ stark aussieht. Dass es unter der Haube teuer und oft sogar schlechter ist, merkt man meist erst, wenn man genauer hinschaut und richtig damit arbeitet.
Warum das so teuer werden kann
Der Mechanismus ist simpel. Er läuft meistens in vier Schritten:
- Zu viel Kontext wird standardmässig mitgeladen
- Jede Anfrage wiederholt dieses Paket erneut
- Prompt-Caching hilft nur temporär
- Nach dem Cache-Reset zahlst du wieder voll
Warum das jetzt zählt, unabhängig vom Tool
Ein letzter Punkt, der mir wichtig ist.
Die Tools und Frameworks, die wir heute für Agent-Gedächtnis nutzen (OpenClaw, Dreaming, Memory Wiki, RAG-Frameworks), sind alle relativ neu und werden sich in den nächsten Monaten noch deutlich verändern. Einige davon wird es in zwei Jahren vielleicht gar nicht mehr geben, andere werden dominieren, die heute noch niemand kennt.
Das ist aktuell einfach der Zustand, mit dem wir leben müssen in dieser Technologie-Phase. Deshalb ist unser 5-Bausteine-Framework bewusst toolunabhängig. Es beschreibt, was ein Agent braucht, um brauchbar zu funktionieren, unabhängig davon, mit welchem Werkzeug du es baust.
Was toolunabhängig bleibt
Die fünf Bausteine sind:
- Identität
- Gedächtnis
- Skills
- Schnittstellen
- Governance
Diese Bausteine wirst du brauchen, egal ob du mit OpenClaw, einem ChatGPT-Agent, Langdock, Glean, Microsoft Copilot oder einem Tool arbeitest, das es heute noch gar nicht gibt.
Solange Sprachmodelle nicht selbst aus der Nutzung lernen, also solange Gewichte eingefroren bleiben, müssen wir uns organisieren.
Konkret heisst das:
- Saubere Prozesse (aufschreiben; z. B. als SOP's)
- Klare Datenstrukturen
- Konsistent gepflegtes Wissen
- Nachvollziehbare Tonalität
Der Agent kann nur so gut sein, wie die Vorarbeit, die dahinter liegt.
Das klingt vielleicht aufwendig, und ehrlich gesagt, das ist es auch. Aber es ist eine Vorarbeit, die sich doppelt auszahlt. Heute bringt sie deinen Agenten zum Laufen. Und morgen, wenn die Tools nochmal einen Sprung machen, bist du schon deutlich weiter, während andere dann erst anfangen zu strukturieren.
Key Takeaways
- Das Sprachmodell selbst lernt nicht mehr dazu, was als Gedächtnis wirkt, ist extern mitgeliefertes Wissen
- Gutes Agent-Gedächtnis arbeitet unserer Ansicht nach in vier Schichten. Immer präsent, episodisch, langfristig destilliert, bei Bedarf abgerufen
- Dreaming simuliert in OpenClaw die menschliche Gedächtnis-Konsolidierung im Schlaf. Erlebnisse werden bewertet, Wichtiges ins Langzeitgedächtnis integriert, Muster extrahiert
- Was ins Gedächtnis gehört, ist eigenes Wissen. Identität, Skills, Schnittstellen und Governance sind andere Bausteine
- Der häufigste Framework-Fehler ist «einfach alles mitschicken». Das kostet viel und verschlechtert oft die Qualität
- Die entscheidende Kennzahl beim Skalieren von Agenten heisst Qualität pro Token
- Wir sind mitten in einer Phase, in der die finale Lösung für Agent-Gedächtnis noch erfunden wird. Karpathys Wiki-Ansatz, Dreaming, Memory-Wikis sind Versuche in dieselbe Richtung
Fazit
Gedächtnis ist der Baustein, bei dem sich am meisten entscheidet und der gleichzeitig am unsichtbarsten ist. Identität siehst du am Output sofort, Skills siehst du an der Aufgabenerledigung, Schnittstellen siehst du an den integrierten Tools.
Gedächtnis bemerkst du meist erst, wenn es fehlt. Typische Symptome sind:
- Wiederholungen
- Fehlender Kontext
- Antworten, die am Thema vorbei gehen
Wer hier Zeit investiert, bekommt einen Agenten, der bei Session zwei nicht bei null anfängt. Der bei Kunde X weiss, was letzten Monat vereinbart wurde. Der sich an Präferenzen hält, nicht weil das Modell dazugelernt hätte, sondern weil das System diszipliniert mitschreibt und gezielt abruft.
Natürlich ist das kein Erinnern im menschlichen Sinn. Keine Emotionen, keine unbewussten Assoziationen, kein Bauchgefühl, das ein Muster erkennt, bevor man es benennen kann.
Aber es ist gut genug, um zuverlässig weiterzumachen. Und mit Konzepten wie Dreaming nähert sich die Architektur den Prinzipien menschlicher Konsolidierung zumindest strukturell an.
Die richtige Lösung ist ziemlich sicher noch nicht gefunden, und genau jetzt wird in diesem Feld noch sichtbar experimentiert.
Nächste Woche geht es um Baustein 3, die Skills.
Bis nächsten Sonntag 👋🏽
Andreas

Kommentare
Melde dich an, um einen Kommentar zu schreiben.
Weiterlesen
 praxis
praxisWie KI zum Betriebssystem wird
Wir bauen gerade unser eigenes KI-System auf. Was wir dabei gelernt haben, gilt für jedes agentische Tool. Die fünf Bausteine: Identität, Gedächtnis, Skills, Schnittstellen und Governance.
Lesen strategie
strategieKI nutzen heisst heute nicht mehr besser prompten
Warum «am System arbeiten» die entscheidende KI-Kompetenz wird. Mit konkreten Beispielen, Zahlen und einem Framework für funktionierende KI-Systeme.
Lesen strategie
strategieWerkzeug, Assistent, System: Die 3 Stufen der KI-Nutzung 2026
Du fragst, KI antwortet. Aber was, wenn sie ganze Aufgaben von A-Z erledigt? Die 3 Stufen der KI-Nutzung, eingeordnet mit eigenen Erfahrungen und konkreten nächsten Schritten.
Lesen